

Table of contents
- Introduction
- The “Data Cascading” Problem Encountered by 92% of AI Practitioners
- From big data to good data
- AI industry turning to data-centric AI
- Data maintenance know-how
- Labeling
- Data augmentation
- Data as a cause of technical debt and what to do about it
- Summary
Introduction
From around 2021, a new AI system development concept called “data-centric AI” has been advocated. In this article, after confirming the problems of conventional “model-centered AI”, we will summarize the overview and trends of data-centered AI and introduce specific know-how on data maintenance.
The “Data Cascading” Problem Encountered by 92% of AI Practitioners
Conventional AI research and development has focused on AI models (such as machine learning models) that are the core of AI systems. It has been customary for AI developers to use various techniques on AI models to improve the accuracy of AI systems to a target value.
Under these circumstances, in May 2021, a Google research team published a paper that critically examined the development philosophy centered on AI models, which has been taken for granted until now . Data Cascade in High Stakes AI ” was announced. The paper considers the impact of training data quality on AI systems.
The above survey was conducted with 53 AI practitioners who participated from all over the world (*Note 1). The survey asked survey participants about the relationship between data and AI development in an interview format. After asking the question, we found that at least 92% (48 people) of the survey participants experienced some kind of data trouble .
The Google research team named AI system troubles caused by insufficient data or low quality data cascades and categorized them as shown in the table below.
| Features of Cascade | Overview | cause |
| Vulnerability in interaction with the physical world | AI systems do not accurately reflect real-world problems | Improper handling of real-world data |
| Lack of expertise in application areas | Lack of expertise on the problem or training data | Excessive reliance on expertise in some tasks |
| Clash of reward systems | Some work related to AI system development and operation is unreasonably cheap | Insufficient setting of incentives Negligence of data |
| Lack of cross-organizational materials | Materials that should be shared by the entire project team are not shared | neglect to prepare data materials |
The schematic diagram of the project process that causes the above cascade and the process that affects it is as follows.
From the schematic diagram above, we can see that various data cascades arise from the early stages of the project, such as “problem definition,” and adversely affect the later stages of the project, such as model evaluation and implementation . In some cases, it can lead to redoing or abandoning the project itself. Furthermore, if multiple data cascades occur, they will accumulate and adversely affect the post-project process .
The research paper attributed the above data cascade to the “Goodness-of-fit”, which measures whether conventional AI projects work well with given data using various indicators. He points out that it was because he was caught up in the development attitude of “goodness related to But goodness-of-fit doesn’t say much about whether the data itself is good enough for the problem you’re trying to solve.
As a new development attitude to prevent data cascade occurrence, the Google research team advocates “Goodness-of-data” instead of Goodness-of-fit. However, regarding the latter, he simply points out that there is no specific evaluation tool yet and that it should be developed in the future.
By the way, the statement in the title of the above research paper, “Everybody wants to work on models, not data,” was made by an Indian AI practitioner in the healthcare field who was one of the research participants. is. This remark is a mockery of the current situation where the development of AI models is given top priority , while data-related tasks such as data collection and labeling, which have a large impact on the performance of AI systems, are not evaluated .
From big data to good data
Andrew, who played an active role as a driving force behind the third AI boom in the United States, is trying to systematize the “Goodness-of-Data” advocated by the aforementioned Google research paper as an AI design concept named “Data-centric AI”. Professor Ng. An overview of data-centric AI is summarized in the presentation ” Chat with Professor Andrew on MLOpes: From Model-Centric to Data-Centric AI ” , which was live-streamed on YouTube in March 2021, and in the presentation slides . I’m here.
Professor Ng’s first collaboration is the recognition that for AI systems, “(learning) data is the code itself .” This perception is quite natural given the fact that the behavior of an AI system is determined by the AI model as well as the training data that trains that model.
Professor Ng expresses the relationship between data and AI systems as “data is food for AI,” and presents the following diagram for further consideration. This expression tries to convey the importance of data quality in AI system development in the same way that the quality of ingredients is as important as cooking technology in cooking. Furthermore , it is clear that data is important, as 80% of man-hours in AI system development are spent on data preparation .
Professor Ng also pointed out that 99% of conventional AI research discusses models, while only 1% discusses data , even though data has a significant impact on the quality of AI systems. To do. As pointed out in the above-mentioned Google research paper, this current situation is due to the fact that while the development of new AI models is the star of AI research, the maintenance of data and discussion of the impact of data have been neglected. can be said to have been formed.
In contrast to the current situation where model-centered research and development is emphasized, Professor Ng will cite numerous examples to demonstrate that improving the quality of data contributes to improving the performance of AI systems. As summarized in the table below, the model-centric approach stalled performance improvement, while switching to the data-centric approach yielded significant performance improvements . These examples show that a data-centric approach to AI system development is superior.
| metal defect detection | solar panel | surface inspection | |
| Base line | 76.20% | 75.68% | 85.05% |
| model centric | +0 | +0.0004 | +0 |
| data-centric | +0.169 | +0.0306 | +0.004 |
Professor Ng also points out that one advantage of data-centric AI development is that it requires less training data than before. An example that proves this advantage is an AI system that predicts the rotational speed of a motor from the voltage applied to it. To clarify the relationship between data quality and AI systems, we will compare the prediction accuracy in the following three cases.
- Case 1: The amount of training data is small and there is a lot of noise such as inconsistencies between data labels.
- Case 2: The amount of training data is large, but the data is noisy.
- Case 3: The amount of training data is small, but the data has little noise.
Comparing the above three cases, Case 2 and Case 3 have almost the same prediction accuracy. From this result, we can see that the important thing in practicing data-centric AI development is not to collect a lot of learning data, but to prepare high-quality data . Based on this situation, Professor Ng expresses the mindset of practicing data-centric AI development as “from big data to good data .”
As a summary of data-centric AI development, Professor Ng preaches the effective use of MLOps . In data-centric AI development, it is necessary to repeatedly improve the data and retrain the AI model using it, and monitor the data and AI model performance that is put into the production environment. Leveraging MLOps is a convenient way to implement these data-centric, iterative processes.
AI industry turning to data-centric AI
Professor Ng founded the startup Landing AI to implement what he advocates for data-centric AI development . The company’s blog features articles related to data-centric AI.
In response to the rise of data-centric AI, on December 14, 2021, the final day of the 2021 conference of NeurlPS, one of the top conferences in AI academia, the NeurlPS Data-Centric AI Workshop , a workshop specializing in data-centric AI, will be held. was held. Through this workshop, it was made known that the development concept of data-centric AI is a research area that deserves attention . In fact, when we called for papers discussing data-centric AI in conjunction with the workshop, we received a large number of papers. A list of accepted papers can be found on the official website of the workshop mentioned above.
Furthermore, from 2022, we will open a website, Data-centric AI Resource Hub , which aims to collect information on data-centric AI . The site contains articles discussing know-how about data-centric AI, as well as videos presented by leading figures in the field.
Data maintenance know-how
In the following, we will introduce three know-how related to data maintenance for practicing data-centric AI development posted on the Data-centric AI Resource Hub.
Labeling
Associate Professor Michael Bernstein of the Department of Computer Science at Stanford University advocates a data labeling method that makes use of the lessons he learned from data labeling in an AI project he was involved in .
According to Associate Professor Bernstein, the lack of consistency in data labeling is not due to the lack of ability of labelers (labelers), but rather to the fact that labeling operations managers do not manage labeling properly . You can Professor Ng’s presentation mentioned above also explained this lack of control in labeling, citing specific examples. For example, in the image below (on the left side of the slide) that shows two iguanas, if you give an instruction to “enclose the iguana’s position in a rectangle”, the instruction will be given in three ways as shown on the right side of the slide. can be interpreted. In order to give instructions that can be interpreted unambiguously in this case, it is also necessary to give instructions on what to do when multiple iguanas are photographed and when iguanas overlap.
In order to eliminate the above-mentioned mismanagement in labeling work, Associate Professor Bernstein clearly defines the entire labeling process, and uses a method called Gated Instruction to prevent differences in labeling by labelers. is recommended. To implement the method, perform the following six items.
- Label many examples yourself before designing the task.
- Give workers fair compensation and treatment.
- Always start with a small pilot.
- We believe that the labeling error was not due to lack of worker skills, but rather to a problem in giving instructions by the manager.
- Train labeling with feedback.
- Hire more full-time workers with fewer people.
For more information on gated instructions, please refer to this paper .
Data augmentation
Professor Anima Anandkumar from Caltech has published an article on data augmentation . In this article, we first list the following three imperfections found in training data in general:
- Domain Gap: The training data used to train an AI model and the data that is actually predicted in the real world are often different.
- Data bias: Collected learning data will contain bias if the collected population has a social bias.
- Noisy data: Ambiguous or messy labeling introduces noise in the labels.
Data augmentation that supplements the training data is effective in overcoming the above constraints. There are two techniques for such data augmentation:
- Self-supervised learning: A technique that uses labeled and unlabeled data to achieve learning effects equal to or better than supervised learning. Unlabeled data is generated by rotating or cropping labeled data.
- Synthetic data: A technique that uses some tool to generate training data.
According to Professor Anandkumar, when performing data augmentation from the perspective of data-centric AI , training data should be prepared so that the boundaries where labeling changes are clear . To explain the “boundary where labeling changes” with reference to dog image recognition, what kind of processing is applied to the dog image so that it is no longer recognized as a dog, and the boundary line between the dog and non-dogs. means
Professor Anandkumar cites SimCLR (A Simple Framework for Contrastive Learning of Visual Representations) as an example of research that focuses on the boundaries of labeling . According to the SimCLR paper published by Professor Jeffrey Hinton et al. We were able to develop a model that greatly surpasses the performance of the same model with one-third the amount.

Data as a cause of technical debt and what to do about it
Google Brain Director D. Sculley has published an article discussing technical debt arising from data imperfections . Technical Debt means the cost of later refurbishment as a result of technical compromises (such as delaying version upgrades). In general, IT systems require ongoing maintenance to avoid technical debt.
In AI systems, technical debt is often thought of as arising from the AI model, but in fact, it also arises from poor maintenance of data . Sculley cites two reasons for this claim:
- The position occupied by AI models in AI systems: AI models occupy less than 5% of the entire AI system source code (“ML Code” in black in the image below) . Data- related processing is 70% .
- Data is the code of the AI system: (Learning) data determines the behavior of the AI system, so the data is now the source code itself (Professor Ng also pointed out above).
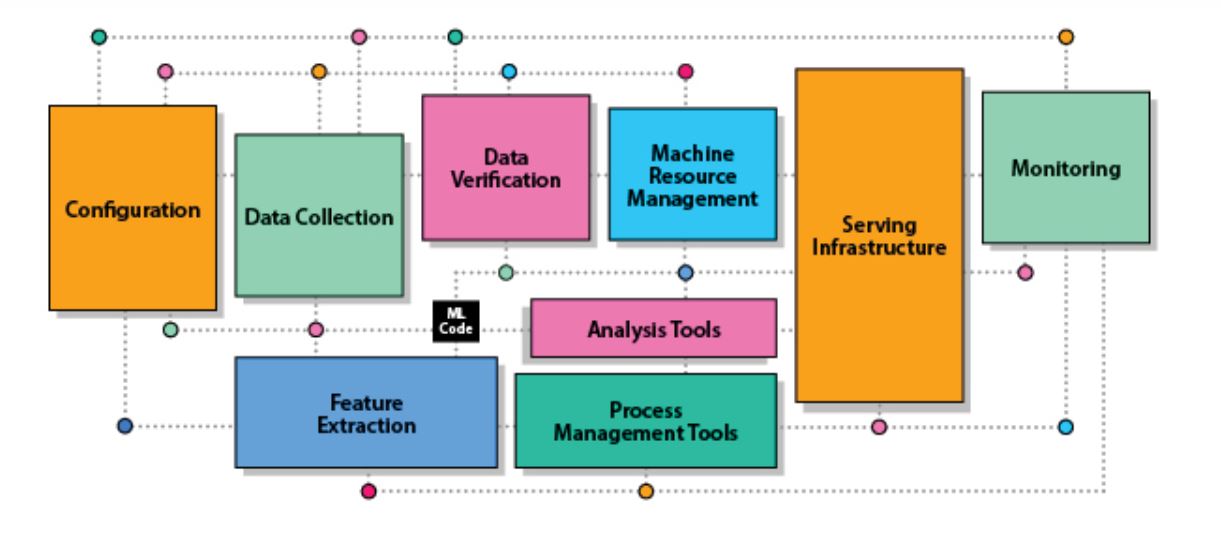
Image source: Quoted by the article author from the Data-centric AI Resource Hub blog post
Sculley cites the following three data management techniques to prevent technical debt from data.
- Data quality auditing and monitoring: Manually or automatically monitor data for early detection of changes in data quality or distribution.
- Data documentation: Create data transparency and accountability documentation. Regarding the specifications of these documents, there is a data sheet proposed by the research team of Microsoft Research et al.
- Creating and Applying Stress Tests: Create stress datasets that deliberately collect improbable or unusual data, then evaluate the implemented model. These stress tests allow us to assess behavior for inputs that were not encountered during training on the learning data.
After describing technical debt caused by data and how to prevent it , Sculley says that continuous maintenance of data will eventually lead to maintaining the quality of AI systems at low cost. is emphasizing.
(* Note 2) In the data sheet advocated by the research team of Microsoft Research et al., it is recommended to fill in the following items.
Overview of datasheets recommended by Microsoft Research et al.
| entry name | Overview |
| Motive | State the reason for creating the dataset and any stakes such as funding. |
| Constitution | Specify the type of data (for example, whether it is text data or image) and the structure of the data, such as the number of data. |
| collection process | Specify how the data was collected and the tools used to collect it. |
| Pretreatment/Cleaning/Labeling | Specify how pretreatment/cleaning/labeling was done. |
| Usage | State what the dataset will be used for, and if there are any tasks it should not be used for. |
| dDstribution | Specify when, how and to whom the dataset will be distributed. |
| Maintenance | Clarify the data management system when and by whom the data set will be managed. |
Summary
Data-centric AI has just begun to attract attention, so systematic knowledge and know-how have not yet been established. However, it is thought that research results based on this idea will be actively implemented in the future, so it is desirable to catch up on the latest information by referring to the Data-centric AI Resource Hub.
In addition, the AI system quality currently discussed in data-centric AI is mostly performance aspects such as accuracy. In addition to performance aspects, AI system quality also includes ethical aspects such as not making biased judgments and not outputting results that include bias . We believe that these ethical aspects can be mitigated through improved data preparation and maintenance. Therefore, ethical efforts in data-centric AI will also be made in the future.

{kind=link}