

Table of Contents
- Supports 24 languages using integrated learning data
- long tail language problem
- Creation of Integrated Learning Data and Its Advantages
- Contributions of native speakers
- Future tasks
- Implemented automatic summarization model “PEGASUS” in Google Docs
- Automatic summarization prior to PEGASUS
- PEGASUS Innovation
- PEGASUS improvements
- Future tasks
- The world’s largest language model “PaLM”
- New AI design concept “Pathways”
- A Breakthrough in Chained Inference
- Supports code generation
- Residual bias
- Future tasks
- Other AI technologies announced
- Three evolutions of Google Maps
- Two useful new features on YouTube
- Improved image quality of Google Meet
- Launch of AI Test Kitchen
- summary
Foreword
From May 11th to 12th, 2022, the annual Google-sponsored developer conference ” Google I/O 2022 ” was held as a hybrid. If you read the article summarizing the keynote speech given by the company’s CEO Sundar Pichai, you can see that a number of AI technologies have been announced. In this article, I will extract and explain the announcements at Google I/O, especially those related to natural language processing.
Supports 24 languages using integrated learning data
At Google I/O 2022, it was announced that Google Translate now supports 24 new languages . Supported languages include Assamese, spoken in northeastern India, and Kurdish, spoken by Kurdish people (see appendix at the end of this article for 24 translation supported languages). Large-scale development of multilingual machine translation was essential to realize this new function. An overview and details of these developments are provided in Google AI research blog posts and papers .
long tail language problem
Machine translation of long-tail languages (niche languages with few users) is difficult because there is overwhelmingly less training data compared to major languages such as English . Since natural language processing research on long-tail languages has not progressed, there is also the difficulty that the method itself for collecting learning data has not been established .
The graph below shows the amount of training data for translation for various languages. The horizontal axis represents the language type, and the vertical axis represents the amount of learning data. If you align the languages so that the language with the largest amount of learning data is on the left, the long-tail languages are on the right side of the graph. Since the distribution of this graph is the same as the long tail , which is the concept of Internet business, niche languages with few users are called long tail languages. In addition, the area colored in red in the graph represents “parallel data”, which means learning data related to correspondence with other languages, and the blue area is learning data for a single language that lacks correspondence with other languages. It stands for “monaural data”. From this graph, we can see that the languages for which parallel data useful for machine translation are maintained are only a small part of the languages spoken in the world .
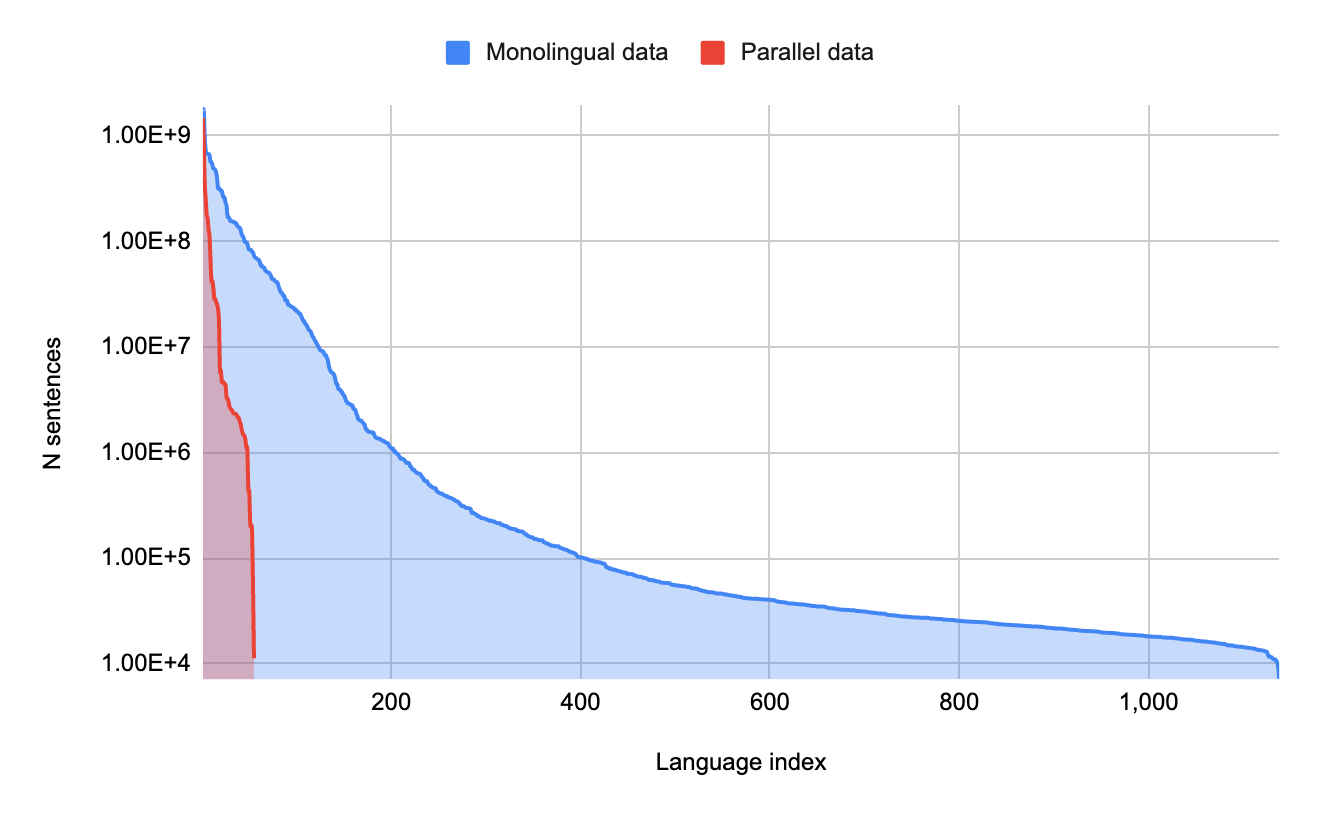
Amount of training data for each language. Image source: Quoted from Google Research blog post
Creation of Integrated Learning Data and Its Advantages
To achieve machine translation of long-tail languages, the Google research team performed the following tasks.
|
As described above, multilingual machine translation including long-tail languages has been realized. In order to evaluate the quality of the multilingual machine translation that has been achieved, the Google research team independently developed a translation quality index RTT LANGID CHRF (* Note 1) was calculated. The calculated results are shown in the graph below. The vertical axis means the RTT LANGID CHRF value, and the horizontal axis means the amount of learning data. Red plots represent languages with rich training data and blue plots with poor training data . It can be seen from the graph that some languages with little training data were able to achieve the same translation quality as languages with abundant training data .
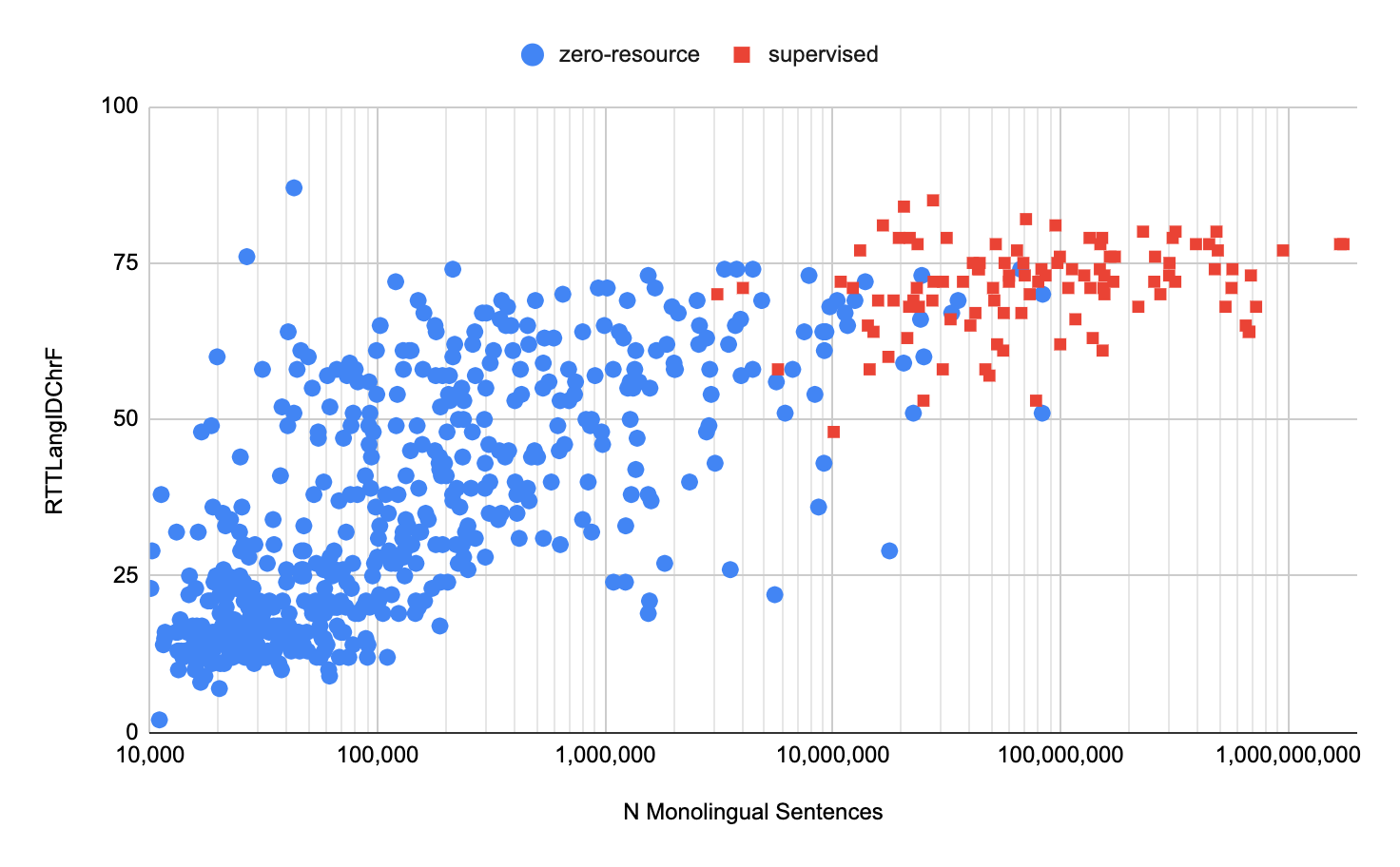
Contributions of native speakers
Native speakers have made significant contributions in evaluating the quality of machine translations of long-tail languages. This is because training data for long-tail languages, which are still in the process of being developed, contain many errors, and correcting these errors cannot be done without the cooperation of native speakers .
The Google research team also investigated the fundamental question of whether the long-tail language community wants multilingual machine translation in the first place. As a result of these studies, we found that the long-tail language community tends to want multilingual machine translation, even if it is of low quality . This result means that the development of machine translation for long-tail languages is extremely meaningful.
Future tasks
The Google research team lists the following three items as future challenges for improving the quality of multilingual machine translation.
|
Implemented automatic summarization model “PEGASUS” in Google Docs
It was also announced that automatic summaries will be implemented in Google Docs . However, the release date of the same function is next year, and the corresponding language is unknown. The feature leverages the revolutionary automatic summarization model PEGASUS . The Google AI research blog post summarizes the research history of the model.
Automatic summarization prior to PEGASUS
Automatic summarization by AI models means performing a Sequence to Sequence task that generates sentences that summarize arbitrary sentences. RNNs used in early language AIs were not good at summarizing long sentences .
The invention of Transformer and Transformer-based language models such as BERT took the development of automatic summary models to a new level. With Transofrmer, I was able to efficiently perform long-form Sequence to Sequence tasks. Also, by using Transformer-based language models, it is now possible to train using unlabeled training data.
PEGASUS Innovation
The automatic summary model PEGASUS , jointly announced by Google and Imperial College London in July 2020, is an evolution of the Transformer-based language model as an automatic summary model.
The innovativeness of PEGASUS lies in the use of GSP (Gap Sentence Prediction) for pre-learning. GSP is learning to predict the entire sentence before masking, given as input a masked part of an unlabeled news article or web document.
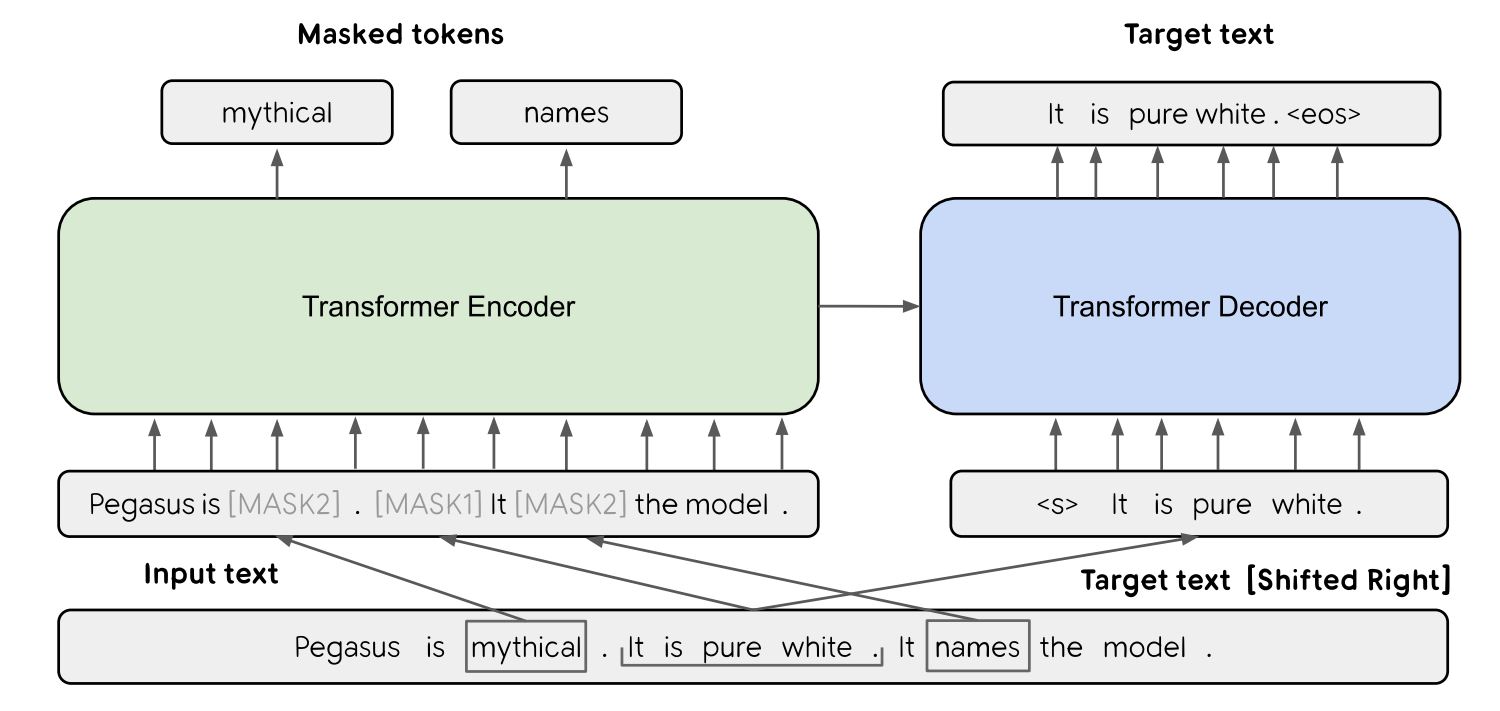
Schematic diagram of GSP. Image source: Quoted from a paper discussing PEGASUS
PEGASUS improvements
When integrating PEGASUS into Google Docs, we needed to further refine our published model. Improvements include the following two items.
|
Future tasks
Such automatic summaries have room for further improvement. There are three issues that need to be addressed in order to improve:
|
The world’s largest language model “PaLM”
Pichai’s keynote speech also mentioned the world’s largest language model “PaLM” (as of May 2022). The official name of the model announced in April 2022 is “Pathways Language Model”, and as the name indicates, the new AI design concept “Pathways” advocated by Google is adopted.
New AI design concept “Pathways”
According to the official Google blog post that introduced Pathways, when comparing this design concept with conventional AI design concepts, it can be summarized as shown in the table below.
| Conventional AI design concept | Pathways |
| Train from scratch for each task . Also, tasks cannot be combined to execute a new task. | The learning of any task can be diverted to other tasks . Tasks can be combined to perform new tasks. |
| Basically unimodal (image recognition only, natural language processing only, etc..) | Multimodal (supports multimedia such as images, sounds, and languages) |
| Dense model (uses all parameters during task execution) | Spurs model (uses only parameters necessary for task execution) (*Note 2) |
A Breakthrough in Chained Inference
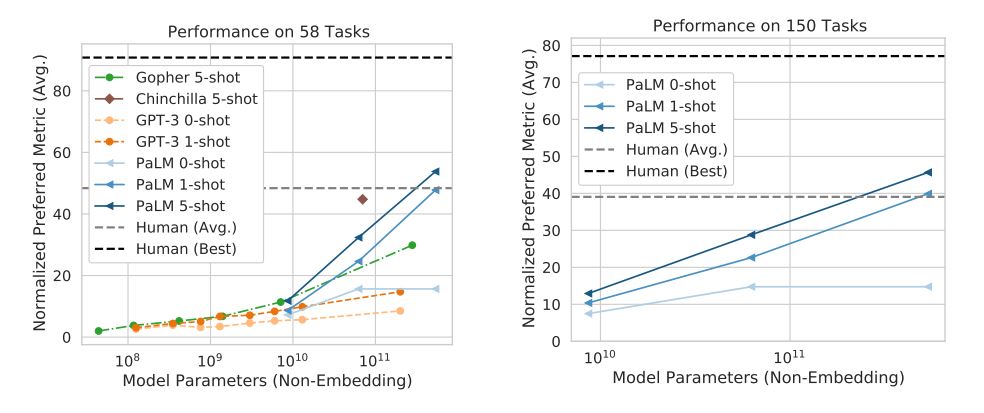
The number of parameters of PaLM that adopted Pathways was 540 billion, which was the largest in the world as of May 2022. However, only some parameters are used during individual task executions. When the performance of this model was measured by Google’s benchmark BIG-bench , which consists of more than 150 language tasks, it showed the highest performance . In the graph below, the vertical axis represents the performance value using BIG-bench, and the horizontal axis represents the model size. From this graph, we can see that PaLM’s performance improves sharply when the model size exceeds 10 billion, but even with the same model, it does not reach the best score of humans .
What is noteworthy about the performance of PaLM is the significant improvement in logical reasoning, which is a weak point of conventional language AIs, including GPT-3 . The Google AI research blog post explaining this improvement includes a graph summarizing the results. From the left, fine-tuned GPT-3, GPT-3 trained specifically for logical reasoning, normal PaLM, PaLM with ” chain of thought ” (described later) , “chain of thought” and ” self-consistency ( It means PaLM that implements one of the latest ensemble techniques called ” self-consistency “, and the accuracy rate of this right PaLM was the highest at 75%.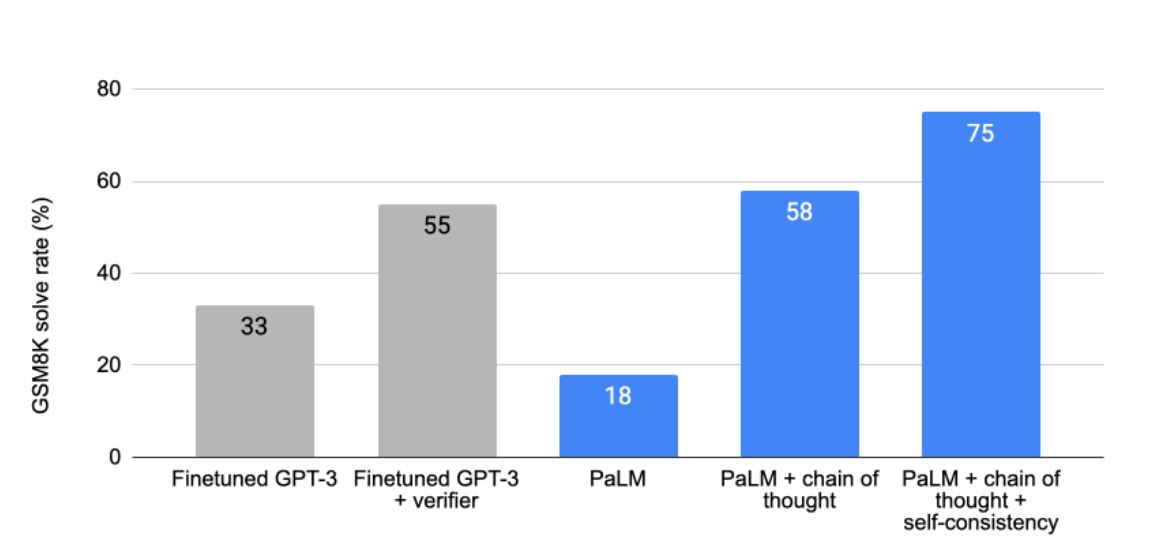
Comparison of PaLM’s logical reasoning ability. Image source: Taken from a Google Research blog post discussing the chain of thought in PaLM
As mentioned above, logical reasoning was improved by adopting a reasoning model called “chain of thought”. Thought chaining refers to the technique of splitting an inference at runtime and then finally combining it . Conventional language models were trained on training data that paired inference conditions and inference conclusions, so there were errors when trying to derive conclusions directly from inference conditions. On the other hand, in the chain of thought, intermediate conclusions are generated from the inference conditions, and the final conclusion is derived using the generated intermediate results. It can be said that this technique exactly mimics the human reasoning process .
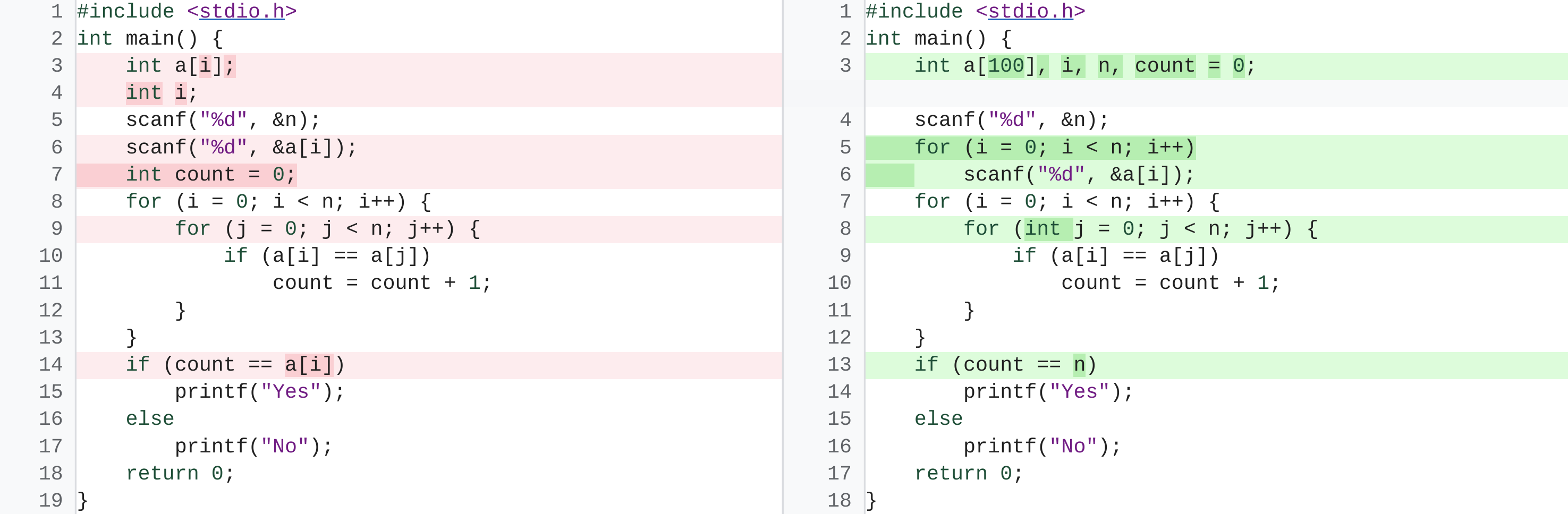
Supports code generation
PaLM also supports code generation like the OpenAI Codex. They perform tasks such as generating code from comments, translating from one programming language to another, and fixing compilation errors.

Residual bias
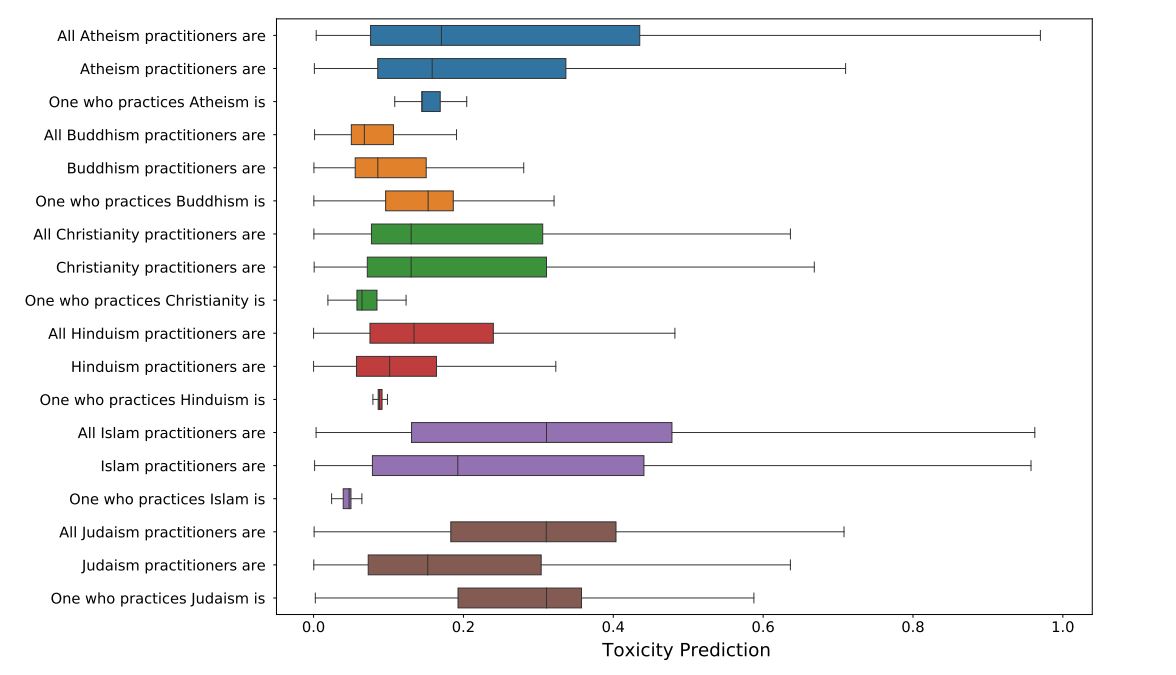
PaLM, like other large-scale language models , produces output that includes gender, occupational, and religious biases . For example, sentences about Islam are relatively more likely to be generated with negative words such as terrorism. The graph below visualizes the probability that generated sentences about each religion contain negative words. A longer colored band indicates a higher probability of containing negative words. We can see that the negative words are relatively more likely to be included in sentences about denominationals, Muslims, and Jews .
Future tasks
In developing a large-scale model that adopts Pathways such as PaLM, the problem is ” how to scale up appropriately “. The recent announcement of DeepMind’s language model “Chinchilla” has revealed that there is room for reconsideration of the relationship between size and performance of dense language models. Conventionally, it was believed that the larger the model size, the better the performance would be in proportion to the size. However, it turned out that not only the model size but also the amount of training data is important for the performance of the language model (*Note 3).
Currently, there are many unknowns about the scaling of the Spurs model employed in PaLM . The main factors related to scaling include model size, training data, computational performance during training, batch size during training, etc. Tradeoffs among these factors will be investigated in the future.
Other AI technologies announced
In Pichai’s keynote speech, Google’s latest AI technology was mentioned in addition to the natural language processing explained above. Below, we briefly introduce four such AI technologies.
Three evolutions of Google Maps
Google Maps has evolved in three ways with AI technology . The first evolution is the ability to detect buildings from satellite images using computer vision and neural networks, making the map more detailed. Specifically, since July 2020, the number of buildings on Google Maps in Africa has increased fivefold, from 60 million to about 300 million, and India and Indonesia have doubled the number of buildings this year. The buildings detected by the above building detection technologies now account for more than 20% of the buildings on the map .

The second evolution is the implementation of immersive views. With this new feature, for example, when you want to visit the Palace of Westminster in England, you can seamlessly see from the photoreal bird’s eye view of the palace to the interior of a nearby restaurant. These drone-like visual experiences are synthesized using static images accumulated by Google using neural rendering , an AI drawing technology . Immersive View will roll out later this year in Los Angeles, London, New York, San Francisco, and Tokyo, with more cities coming soon.
The third is live view. This function uses AR to superimpose arrows and other elements on camera images of the cityscape to guide the user to their destination . Furthermore, it is possible to realize a location information game that displays a dragon in the cityscape. This function applies AI technology called global localization.
Two useful new features on YouTube
Two new features using AI technology have also been added to YouTube. The first new feature is the automatic generation of chapters introduced last year . With chapters, your viewers can easily reach the parts of interest even in long videos. As of May 2022, there are 8 million videos with automatically generated chapters, and we plan to increase it to 80 million in the next year. This function utilizes technology developed by DeepMind (*Note 4).
The second is machine translation of subtitles in YouTube videos played on smartphones, and supports 16 languages. From June 2022, we will support machine translation of YouTube video subtitles in Ukraine, aiming to provide accurate information about the invasion of Ukraine.
Improved image quality of Google Meet
Google Meet, an online meeting tool provided by Google, now uses AI technology to display people’s skin colors more appropriately . This image quality improvement solves the problem that people of color were not able to reproduce the actual skin color properly unless they implemented computer vision that could distinguish a wide range of skin tones. was done for
With the cooperation of Dr. Ellis Monk, a sociologist affiliated with Harvard University, the above image quality improvement conforms to the “Monk Skin Tone,” which is a skin color scale (gradation) devised by Dr. Ellis Monk.
Launch of AI Test Kitchen
Last May, Google announced LaMDA , a language model focused on human conversation. The model has been tested by thousands of Googlers and has seen a significant improvement in quality with fewer inaccurate and offensive responses.
Based on these test results, we launched AI Test Kitchen , a website that allows non-Googlers to participate in LaMDA testing . Through the site, you can participate in three tests:
|

In addition, AI Test Kitchen will open access within the next few months, and at first we will ask academics such as AI researchers, social scientists, and human rights experts to participate in the test. We are planning to increase the number of people.
Summary
As you can see from the above announcements, Google still leads the world in AI research. When it comes to natural language processing, the Pathways model proposed by the company is likely to become the standard architecture for future language model development . This is because the sparsity characteristic of this architecture is more similar to the human brain than existing high-density models, and this similarity is believed to contribute to the realization of AGI.

{kind=link}