

Table of Contents
- 1 Introduction
- 2 Deepfake overview
- 2.1 Face image processing and classification
- 2.2 Speech processing and classification
- References
1 Introduction
The image below looks like a photo of a real person (deep learning), but in reality, the people in the photo are all non-existent people. All of them are portraits generated using deep learning technology called GAN.
The first GAN model was announced in 2014 by a research group led by Ian Goodfellow and Yoshua Bengio, who were doing research at the University of Montreal at the time [2].
Since then, as the computational power of GPUs for deep learning has improved significantly, researchers around the world have improved models, and GAN technology has evolved at an exponential rate. Today, not only can it generate images that are too detailed and realistic to be discerned by humans, but it can also convert video in real time and generate images from text.
“GANs are the most interesting idea of the last decade,” said Yann LeCun, one of the leading experts in deep learning. On the other hand, the rapid evolution of technology has caused various social phenomena and problems.

“Deepfake” is one of the technologies that are causing a particularly big social problem among AI technologies that have evolved rapidly in recent years.
According to a report by a research group at University College London (UCL), “AI-enabled future crime” [3], published in Crime Science, August 2020. concludes that deepfakes are one of the most serious and imminent threats among AI crimes.
In fact, since the term deepfake appeared in 2017, the number of fake videos in the Internet space has increased rapidly, and in September 2020, Facebook announced that it will eliminate fake videos that are manipulated (generated) by AI. The social impact and concerns continue to grow, such as announcing a management policy that says,
The rapid evolution of deepfake technology has a lot to do with the development of technologies that can generate real-like data, such as autoencoders and GAN.
These technologies are highly versatile and useful, and are expected to bring about changes in various industries. It is a technology that can be abused depending on how it is used, and there are already many such cases.
In this white paper, we will look back on the evolution of deepfake and its underlying technology, and consider future social changes and technological trends.
2 Deepfake overview
“President Trump is a hopeless idiot.” In early 2018, a video of former President Barack Obama (
However, the video was a fake video created by BuzzFeed and actor/director Jordan Peele, intended to warn about the problems rapidly evolving technology poses to society. In this way, videos synthesized for the purpose of making it appear as if the person is performing actions that they are not actually doing or as if they are speaking are called “fake videos” and are a major social problem. is causing
“Deepfake” is a general term for technology that creates such fake videos with high accuracy using deep learning technology.

Deepfake is a synthesis technology that consists of several elements, but it can be broadly divided into two technical elements: ” face image processing ” and ” voice processing “[5]. Both of these two technologies have greatly evolved with the evolution of deep learning technology. These two techniques are described in detail below.
2.1 Face image processing and classification
Face image processing (Face Manipulation) is closely related to the evolution of technologies for generating data such as deep learning and GAN, and there is an aspect that has promoted mutual evolution.
Compared to problem settings such as “general object recognition,” which identifies a wide range of images such as cars and animals, face image processing is a problem setting that greatly limits the target of data, and collects a large amount of data. It has the advantage of being easy to
In addition, since it is relatively easy to collect data identified as the same person (data with the same attributes) by using web searches, etc., both the quality and quantity of data can be improved. It can be said that good materials for upgrading were prepared.
In machine learning technologies such as deep learning, the quality of the data provided to the model is directly linked to the quality of the output results and results, so having high-quality data plays a major role in the evolution of the technology.
In the field of face image processing, the advancement of technology has created a virtuous cycle in which more researchers and engineers have been able to organize data, further promoting the evolution of technology, and the technology has evolved rapidly in a short period of time. In addition, some of the technologies that were born there are also being used in fields other than face image processing as highly versatile technologies.
According to “DeepFakes and Beyond: A Survey of Face Manipulation and Fake Detection” [6], face image processing is divided into 1) face generation (Entire Face Synthesis), 2) face replacement (Identity Swap), based on technology and application. ), 3) attribute manipulation, and 4) expression swap.
When the word “deepfake” is taken in a broad sense, it includes all of these technologies in the sense of creating non-existent data, but among them, deepfake technology is the most well-known and causes major social problems. What we have is “ Identity Swap ”. Techniques in each category are described below.
2.1.1 Entire Face Synthesis
The first category is “face generation” technology that can generate a fictitious human face that does not actually exist. As for industrial applications, it is expected to create characters in games and use fictitious models for advertisements.
Such characters and photographs have a high degree of freedom in terms of copyrights and portrait rights, and it is expected that they will be able to be produced to suit the purpose while keeping production and photography costs down.
On the other hand, there is also the danger of being used to create fake profiles on SNS.

2.1.2 Face Swap (Identity Swap)
The second category is
Approaches can be roughly divided into two types: 1) a method using classical computer graphics (CG) technology and 2) a method using deep learning technology. The classical approach requires a lot of labor in addition to advanced specialized knowledge and equipment such as CG, but the use of deep learning technology has made it possible to easily create natural images and videos. .
As an industrial application, it is expected to be used in production sites such as movies and video works. However, as the technology evolves, it is being abused for purposes such as fabricating evidence videos, fraud, and generating pornographic videos, and has already resulted in arrests in several countries, including Japan.
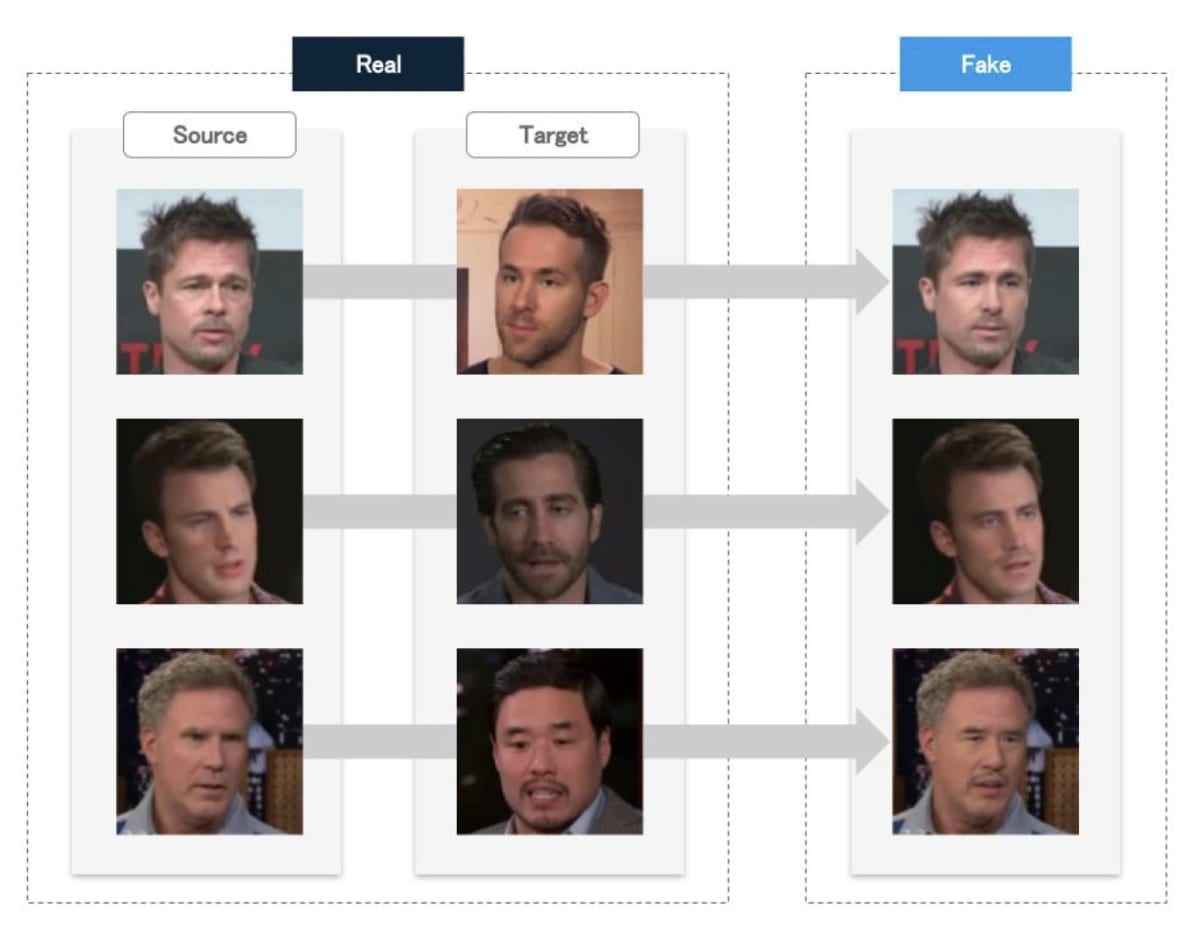
” Datasets ” , which are large collections of real videos (images) and fake videos, have greatly contributed to the evolution of face-swapping technology.
Fake videos include those created by classical methods and those created using the deepfake technology of the time. According to [6], fake video datasets can be classified into two types: first generation and second generation
The quality of facial image synthesis is low, the difference between the
On the other hand, the quality of the second-generation data set has improved significantly, and the variety of scenes has increased.
Various scenarios such as those shot indoors and outdoors are prepared, and there are various variations of videos such as the lighting of the people appearing in the video, the distance from the camera, and the pose. . In addition, as a result of verifying with AI that discriminates several fake videos, the result is that it is more difficult to detect fake videos in the second generation dataset than in the first generation dataset.
2.1.3 Attribute Manipulation
The third category is technology that changes or modifies attributes that characterize a face, such as hairstyle, gender, and age. As an industrial application, it is expected that it will be possible to imagine the completed image before surgery by using it in simulations in cosmetic and orthopedic surgery.
In addition, since it is possible to freely change age and attributes in movies and dramas, it is expected to revolutionize the production process that mainly focuses on special makeup.
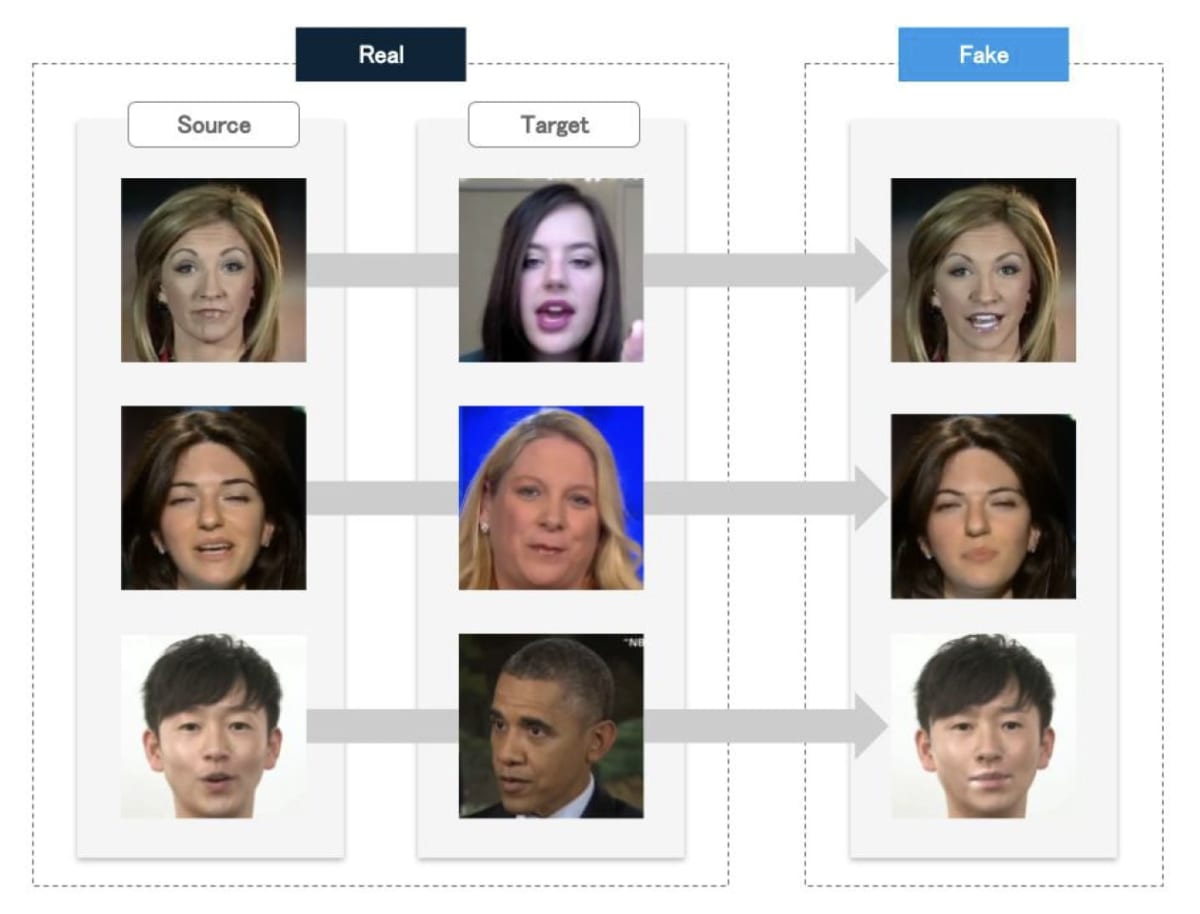
2.1.4 Expression Swap
The fourth category is technology that manipulates and modifies human facial expressions in videos and images. As for industrial applications, it is a technology that is industrially expected to be used for video production, editing, online meetings, and YouTube avatar operation.
On the other hand, it has been suggested that it may be used for fraud and fraudulent opinion guidance, and this technology is also used in the famous fake video of Mr. Mark Zuckerberg[12][6].

2.2 Speech processing and classification
As mentioned above, deepfake is a technology realized by combining video synthesis and audio synthesis. Here, the latter speech synthesis technology will be described.
Similar to video synthesis technology, voice synthesis technology is also a technological area that has rapidly evolved over the past few years along with the evolution of deep learning technology[13].
In general, speech processing consists of two fields: speech recognition (speech-to-text), which converts speech into text, and speech synthesis (text-to-speech), which creates speech data from text. [13][14], and research has been conducted in both fields for a long time.
In addition to these two fields, the technical field of voice cloning , which replicates the voice of a specific person, has developed rapidly in the last few years, and is often used as a deepfake technology. Techniques in each category are described below.
2.2.1 Speech recognition
Speech recognition is a general term for technologies for computers to recognize the contents of speech data, and mainly refers to technologies for converting human speech into text. Speech recognition is used in various situations such as smart home appliances, smartphones, and computer input.
Conventional speech recognition technology is generally realized by combining various components such as 1) acoustic analysis, 2) decoder, and data (dictionary) such as 3) acoustic model and 4) language model.
It was targeted. Since each component was often researched and developed separately, in order to improve the overall performance of speech recognition, in addition to improving the performance of each process, these technologies were appropriately integrated (concatenated). I needed the technology to do that.
As a result, previous processing often affects the performance of subsequent processing, and it is generally known that achieving high performance as a whole is a technically difficult problem.
On the other hand, methods based on deep learning, which have grown rapidly in recent years, integrate multiple or multiple processes among the above processes. As a result, the pipeline as a whole has been simplified and its flexibility has increased. At the same time, the increase in the amount of data and the development of computer technology have boosted the accuracy of speech recognition dramatically.
Products that employ deep learning-based approaches include “Alexa Conversations” [15].
2.2.2 Text-to-speech
Contrary to speech recognition, a technique for outputting synthesized speech is called speech synthesis . Among them, a technique for synthesizing speech from text as input is called text -to-speech ( TTS ).
With conventional technology, unnatural intonation and connections between words were conspicuous, but in recent years, as methods based on deep learning have become common, the performance of technology in this field has improved dramatically. there is
In addition to being able to express the intonation of long sentences, it has become possible to synthesize natural speech, and it has also become possible to switch between multiple speakers and control tones and emotions. Subsequent improved versions have been put to practical use in various places, such as the Google Assistant and Google Cloud’s multilingual speech synthesis service.
Text-to-speech synthesis technology is industrially applied as an example of text-to-speech reading. There are a wide variety of applications, such as voice guidance for users while driving, virtual assistants, interfaces for visually impaired people, etc., and many services and products have already been realized with the above technologies.
2.2.3 Voice Cloning
As an advanced form of speech synthesis technology, a technology was born that can simultaneously receive the voice of a specific speaker as an input in addition to text, synthesize and output voice as if that person were speaking. Such technology is called voice cloning and is often used in deepfakes.
Conventionally, it was a difficult technology to handle because it required advanced technology and collecting a large amount of voice data of the speaker to be cloned. It is possible.
Voice cloning technology already has several industrial applications, such as the creation of videos conveying important messages in the voice of the deceased (although its pros and cons are debatable), and the automatic creation of web radios from blogs.・Already used for purposes such as distribution.
It is also expected to restore the voices of people who have lost their voices, such as ALS patients, to support communication, and to be applied to the production of dubbed videos. Furthermore, it is also used for editing purposes such as partially correcting long audio data recorded for radio or distribution, or audio data that is difficult to re-record.
On the other hand, there have already been cases where it has been misused for purposes such as fraud, and it is also a deep learning that can cause a great loss to society if it is misused.

{kind=link}